Featured Work
Designing for AI Systems
AI Decision-Support Experience
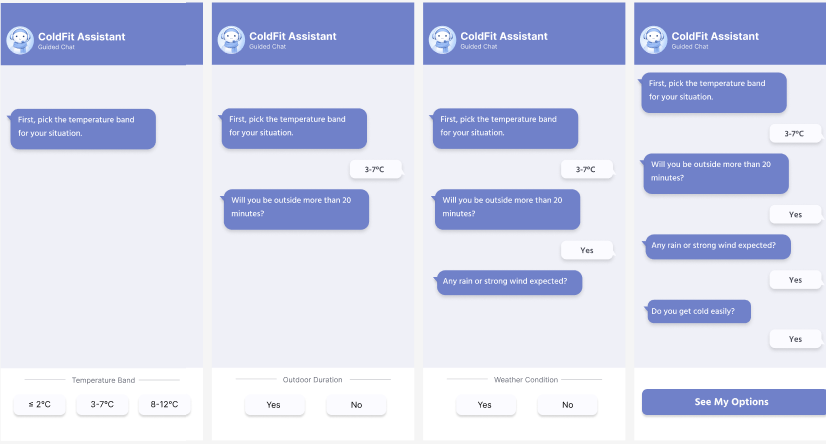
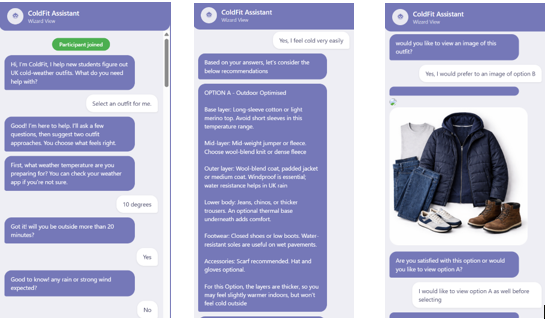
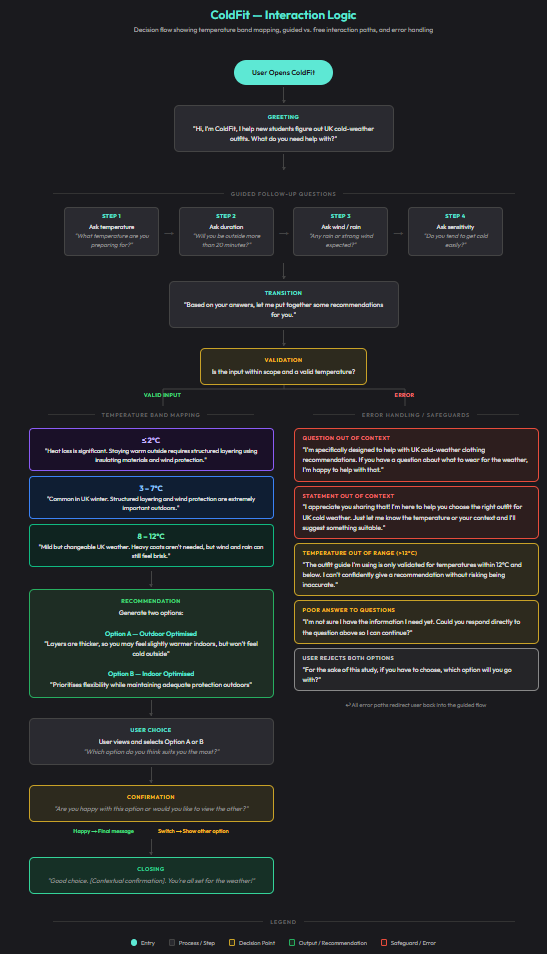
ColdFit
A multimodal AI clothing assistant that helps international students make confident, climate-appropriate clothing decisions in UK winter. I designed the interaction flow, recommendation language, visual-output strategy, and study plan, then measured how different interface structures affected autonomy, effort, trust, and decision confidence.
View Case Study
Study Conducted
Educational Micro-Intervention
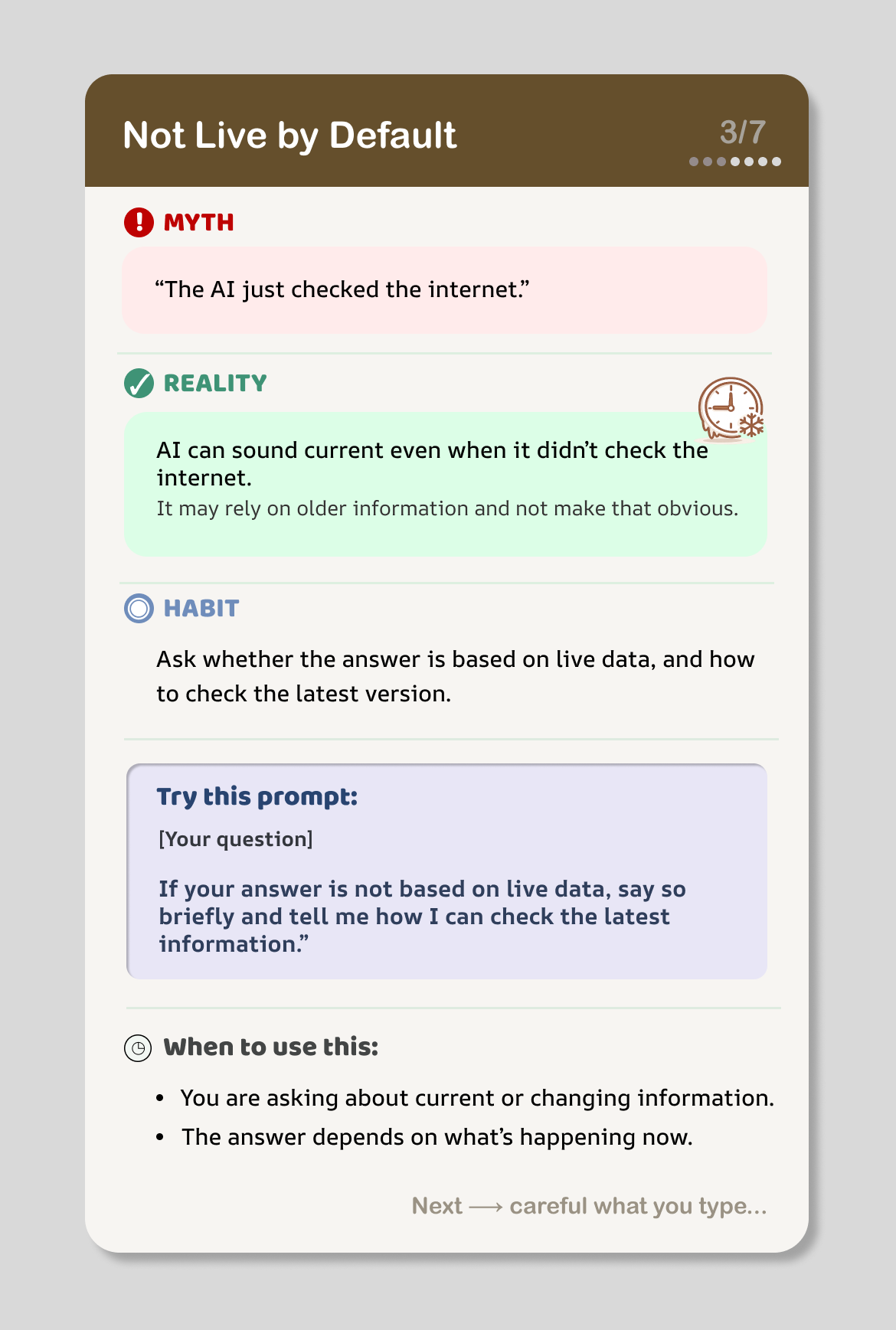
LLM Literacy Cards
Seven myth → reality → habit cards targeting common LLM misconceptions. Built a three-layer LLM-as-a-judge evaluation pipeline and ran a Prolific study (n=49), showing large belief change (d=0.89) and medium–large shifts in scenario responses (d=0.71).
View Case Study